


5 Ways to Fix Cloudflare Error Code 1020
Scraping a website only to get slapped with “Access Denied (Error Code 1020)” can be incredibly frustrating. You set everything up right—your scripts are running, the target page loads fine in your browser—and suddenly, your scraper gets blocked.
This specific error is tied to Cloudflare’s firewall. It’s not a bug, and it’s not temporary. It means your request has violated one of the site’s security rules. Whether it’s your IP, headers, or even how your browser behaves, something triggered an alert.
In this guide, we’ll walk through five reliable techniques to avoid error code 1020 and keep your scraper running smoothly.
Let’s break it down.
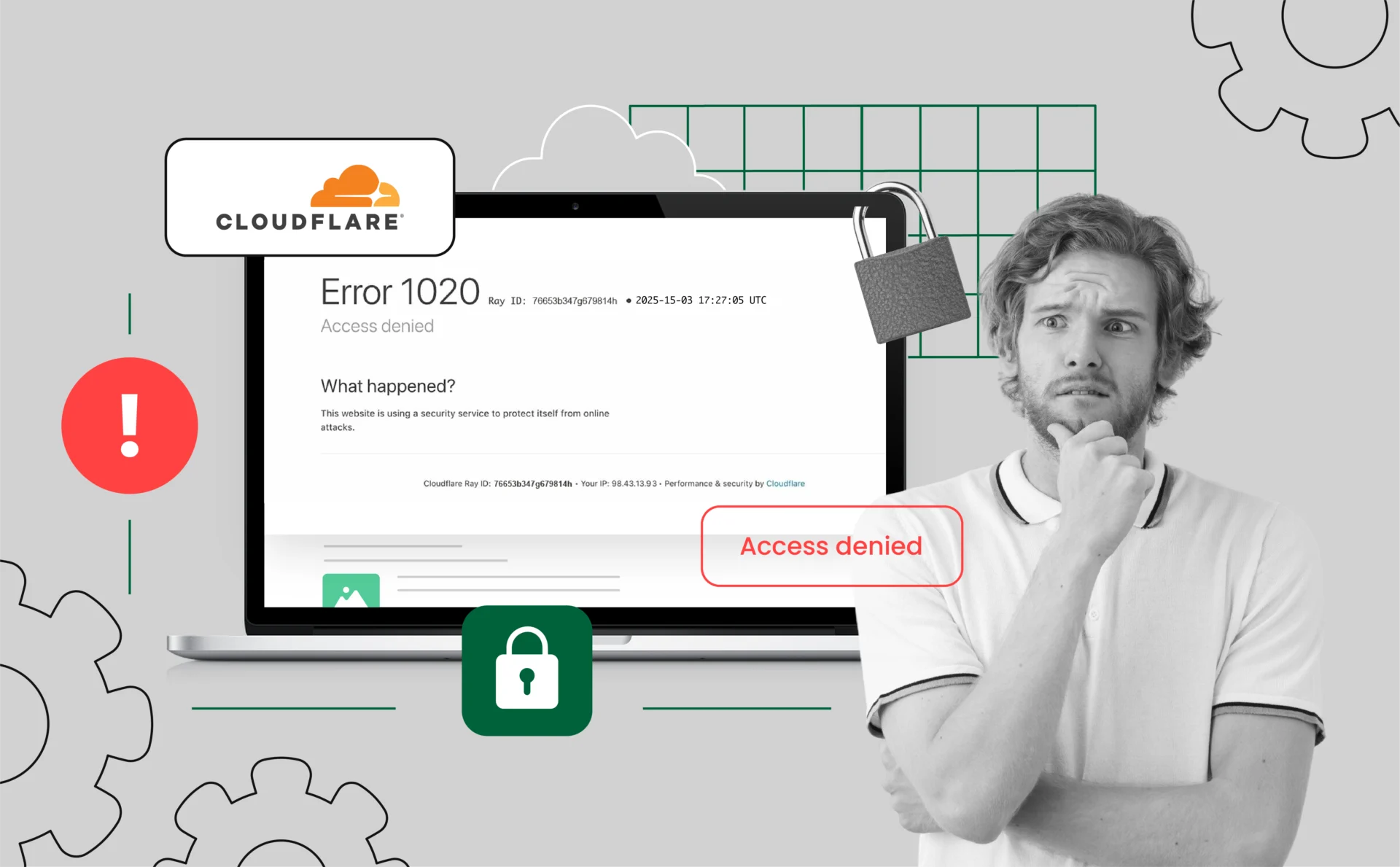
What Is Error Code 1020?
Error code 1020 is Cloudflare’s way of telling you that you’ve triggered a firewall rule set by the website owner. Unlike a generic 403 or 404, this one means your connection didn’t just fail—it was actively blocked.
Cloudflare doesn’t set these rules by default. Site admins use them to block suspicious traffic based on things like IP behavior, request patterns, user-agent strings, or how the browser interacts with the page. If your request doesn’t pass those checks, Cloudflare cuts you off before the page even loads.
What makes this error tricky is that you won’t always know what rule you violated. It could be as simple as sending too many requests in a short time, or as complex as failing a browser fingerprint check. That’s why fixing it usually takes more than one tweak.
You’re not just trying to load a page—you’re trying to look like a real, unique visitor each time.
1. Use Rotating Residential Proxies
If you’re scraping at scale, you need to think about your IP. Cloudflare flags IPs that send too many requests in too little time. That’s when rotating proxies come in handy.
A rotating proxy setup changes your IP every time you make a request. This means Cloudflare can’t track your IP, and you avoid hitting rate limits or getting blocked. Residential proxies are the way to go—they look like they belong to real users, which is harder for Cloudflare to spot compared to data center proxies.
If you’re serious about scraping, residential proxies are your best bet. You get clean, fresh IPs every time, and they help avoid detection while scraping large amounts of data. NodeMaven makes this easy, with rotating residential proxies that blend seamlessly with your scraping workflow.
2. Customize and Rotate User-Agent Headers
Your User-Agent is the digital fingerprint of your browser. It tells websites what browser and device you’re using. If you’re scraping, using a default bot-like User-Agent will get you flagged quickly.
To bypass error code 1020, you need to change your User-Agent to something more like a regular user’s. Rotating your User-Agent every so often makes it look like different people are accessing the website, which reduces the chance of being blocked.
By keeping your User-Agent fresh and rotating it regularly, you can avoid triggering Cloudflare’s security measures. Keep your scraping setup smooth and stealthy.
3. Mask Headless Browsers
If you’re using automation tools like Selenium or Playwright to scrape, Cloudflare can easily spot you. Why? Because these headless browsers leave obvious clues that you’re not a regular user. They have things like the HeadlessChrome flag or missing browser fingerprints, which are dead giveaways.
To avoid being blocked, you need to mask those clues. Multilogin helps with this by providing a more natural browsing environment, reducing the chance of detection when using headless browsers. It removes the common signs of automation and allows your scraper to work without hitting Cloudflare’s radar.
The goal is to make your scraping look as much like human browsing as possible. With the right setup, you can avoid the issues that trigger error code 1020 and scrape freely.
4. Respect Rate Limits and Delays
When scraping, one of the easiest ways to get blocked by Cloudflare is by making too many requests too quickly. If you hit a page multiple times in a short period, it’ll look suspicious, and you’ll get the dreaded error code 1020.
To avoid this, you need to respect rate limits and introduce delays between your requests. This doesn’t mean you have to slow down drastically—it’s about making your scraping look like normal human behavior.
You can use Multilogin to control the speed and frequency of your requests, making sure you don’t flood the site with too much traffic. You can randomize the timing between requests and ensure you’re acting like a real user browsing through the website.
By pacing yourself, you reduce the risk of triggering Cloudflare’s rate-limiting rules and keep your scraper running smoothly.
5. Use Multilogin for Efficient Web Scraping
Multilogin helps simplify the process and make scraping more efficient. Here’s how:
Key Features of Multilogin for Web Scraping
- Unique Digital Fingerprints: Multilogin creates separate browser profiles, each with its own fingerprint, including IP address, user-agent, and browser version. This makes each profile appear as a different user, lowering the chances of getting banned or blocked.
- Proxy Integration: Seamlessly integrates with proxies, allowing you to use different IPs when scraping. This keeps your activities anonymous and helps prevent IP blocks.
- Automation Capabilities: Multilogin supports automation tools like Selenium, Puppeteer, and Playwright. This lets you automate tasks across multiple profiles, making it perfect for large-scale scraping projects.
- Geo-Restriction Bypass: With a wide range of high-quality proxies, Multilogin helps you bypass geo-restrictions, so you can scrape data from region-specific sites and get valuable local insights.
Benefits of Using Multilogin for Web Scraping
- Enhanced Anonymity: By mimicking real user behavior and masking digital fingerprints, Multilogin makes sure your scraping remains undetected, reducing the chances of being blocked by websites.
- Efficient Data Collection: With the ability to automate tasks and manage multiple profiles, Multilogin speeds up data collection. You can focus on analyzing the data rather than dealing with technical setups.
Web scraping can get complicated, especially when you run into anti-scraping barriers like Cloudflare’s error code 1020. But with the right tools, you won’t face any blockers.
Conclusion
- Error code 1020 can be bypassed with the right tools and techniques.
- Use Multilogin for advanced proxy rotation, headless browser masking, and automation.
- Key strategies include:
- Rotating proxies
- Customizing and rotating User-Agent headers
- Respecting rate limits




