How to Scrape All of a Person’s Tweets: Complete Guide for Reliable Data
Twitter (X) is one of the most valuable sources of real-time data, but scraping tweets from a user profile can be tricky due to anti-bot protections. In this article, we’ll show you exactly how to do it safely and efficiently.
You’ll learn how to:
- Set up a Multilogin browser profile with realistic fingerprints and proxies
- Navigate Twitter profiles and handle infinite scrolling
- Extract complete tweet data, including text, media, and engagement metrics
- Manage sessions to maintain login states and resume scraping tasks
- Avoid detection, rate limits, and other common scraping challenges
Why Antidetect Browsers Are Essential for Twitter Scraping
Twitter has implemented advanced detection systems that can identify and block automated scraping attempts. These systems analyze browser fingerprints, IP addresses, user behavior patterns, and session data to distinguish between human users and bots. This is where antidetect browsers become crucial.
Multilogin antidetect browser offers the perfect solution for Twitter data extraction by creating authentic browser profiles that mimic real user behavior. Unlike traditional scraping tools, Multilogin provides:
- Unique browser fingerprints for each session
- IP rotation capabilities to avoid detection
- Real browser environments that appear completely natural to Twitter’s systems
- Session persistence to maintain login states across scraping sessions
New to web scraping? Learn the basics and key concepts in our guide on What is Web Scraping to get started with data extraction effectively.
Is It Legal to Scrape Twitter Data?
Before exploring the technical aspects, it’s important to understand the legal and platform rules.
In September 2023, X (formerly Twitter) updated its Terms of Service to explicitly prohibit crawling, scraping, or automated data collection without prior written consent. Violating these rules can lead to account suspension, IP bans, or legal action from the platform.
Even if content is publicly visible, you must also consider privacy and data protection laws such as GDPR when handling user data, especially for analytics, profiling, or redistribution.
For compliant access, the safest approach is to use X’s official API, which provides structured data under defined limits and conditions. While the API may restrict volume or scope, it ensures your collection is aligned with platform policies. Browser-based automation may still be used for operational purposes, but only with careful attention to legal compliance and X’s updated rules.
Complete Guide: Scraping All Tweets from a User Profile
This section explains how to systematically collect all tweets from a user profile, covering setup, extraction tools, scrolling, and session management for reliable results.
Want to scrape tweets safely and efficiently? Our detailed Scraping Twitter Guide walks you through every step using the right tools and techniques.
Step 1: Set Up Your Multilogin Profiles
First, configure your Multilogin antidetect browser for optimal Twitter scraping:
- Create a new browser profile with unique fingerprints
- Select a residential proxy from a relevant geographic location
- Configure realistic browser settings (timezone, language, screen resolution)
- Enable cookie management to maintain session persistence
Step 2: Implement the Scraping Logic — Choose an Extraction Tool
Pick a tool that runs inside or alongside your Multilogin profile:
- Browser extension — install a visual scraper (e.g., Web Scraper) in the profile, map tweet blocks, export CSV/JSON (easy, quick).
- Automation script — connect Selenium/Playwright to Multilogin’s remote port, script navigation, scrolling, DOM reads and save JSON/NDJSON (flexible, scalable).
- Official API — use X/Twitter API when available for structured data; fall back to DOM scraping only for missing fields.
- Hybrid — use API for IDs/metadata and the browser to fetch full content or media as needed.
Quick wiring notes: add extensions before launch, connect scripts via the remote debugging/WebDriver port, run headed profiles for realism, and rotate profiles/proxies to avoid rate limits.
Step 3: Navigate to the Target Profile
Access the Twitter profile you want to scrape using your configured Multilogin browser. The antidetect technology ensures your requests appear as legitimate user traffic, significantly reducing the risk of detection or blocking.
Step 4: Handle Twitter’s Infinite Scroll
Twitter uses infinite scrolling to load tweets dynamically. This presents unique challenges:
- Scroll timing: Implement realistic scroll patterns that mimic human behavior
- Content loading: Wait for new tweets to load completely before extracting data
- Rate limiting: Avoid scrolling too quickly to prevent triggering anti-bot measures
Step 5: Extract Tweet Data
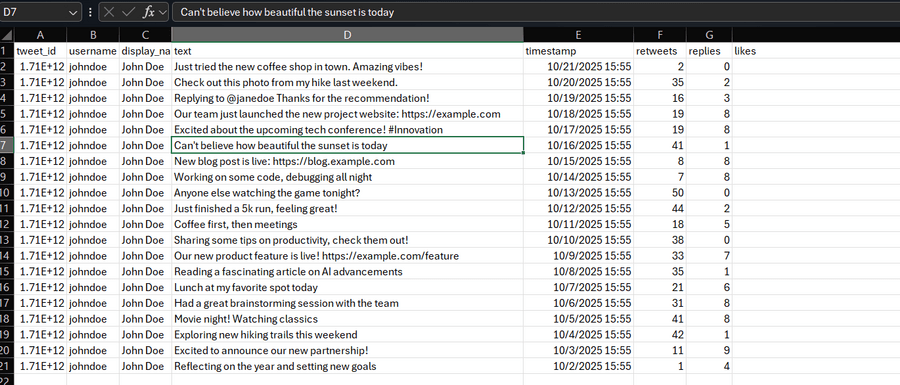
Focus on collecting comprehensive data points from each tweet:
- Tweet text content and metadata
- Publication timestamps
- Engagement metrics (likes, retweets, replies)
- Media attachments (images, videos, links)
- Reply threads and conversation context
Need to collect images from a website? Explore 9 simple ways to do it in our article on Extracting Images from Websites.
Step 6: Manage Session Persistence
Multilogin’s session management capabilities allow you to:
- Maintain login states across multiple scraping sessions
- Resume interrupted scraping operations
- Distribute scraping across multiple browser profiles to increase efficiency
Benefits of Using Multilogin for Twitter Scraping
Enhanced Reliability
Most scraping tools struggle with bans and broken sessions. Multilogin’s antidetect environment ensures:
- Consistent access to Twitter content that appears as genuine user traffic
- Reduced risk of IP bans or temporary restrictions
- Stable long-term performance during continuous scraping tasks
Scalable Infrastructure
Multilogin makes it easy to scale Twitter scraping operations without detection:
- Run multiple isolated browser sessions simultaneously
- Automate profile creation, management, and cleanup
- Use smart proxy rotation and profile distribution to balance workloads
Higher Data Quality
A realistic browsing environment improves the accuracy of collected data:
- Full page rendering and JavaScript execution for dynamic content
- Access to infinite scroll, replies, and embedded media
- Reliable extraction of all visible user data, including text, metrics, and timestamps
Operational Efficiency
Multilogin helps maintain smooth, continuous operations through:
- Persistent login sessions across scraping cycles
- Easy profile recovery and resumption after interruptions
- Centralized control for managing large-scale scraping environments
Common Challenges and Solutions
Challenge 1: Login Requirements
Problem: Many profiles and timelines require authentication; frequent re-logins break sessions and increase detection risk.
Solution: Use Multilogin’s cookie and storage management to persist authenticated sessions.
Actionable steps:
- Save and reuse cookies / localStorage between runs instead of logging in each time.
- Maintain a pool of pre-authenticated profiles for parallel jobs.
- Rotate which profile performs sensitive actions to spread risk.
- Periodically refresh session tokens with a controlled log-in flow (not every run).
Challenge 2: Content Loading Delays and Race Conditions
Problem: Infinite scroll and lazy-loaded elements may not be present when extraction runs, causing missed tweets or partial records.
Solution: Implement intelligent waiting and detection mechanisms that confirm content has fully loaded before extraction.
Actionable steps:
- Wait for stable DOM indicators (e.g., presence of the last tweet node, or no new nodes after X seconds).
- Use MutationObservers or explicit “wait for selector” with timeouts instead of fixed sleep intervals.
- Backfill missed items by scanning backward from the last-known tweet ID.
- Add a short randomized delay after scrolls to mimic human pause.
Challenge 3: Anti-Bot Detection and Fingerprint Mismatch
Problem: Aggressive anti-bot systems detect scripted patterns, unusual fingerprints, or headless browsers.
Solution: Combine Multilogin’s fingerprint randomization with behavioral mimicry to blend in.
Actionable steps:
- Run headed (non-headless) sessions and avoid browser flags that reveal automation.
- Randomize mouse movements, typing speed, and scroll cadence.
- Keep timezone, language, and resolution consistent with chosen geo-proxy.
- Test profiles with a fingerprint checker before full runs.
Challenge 4: Rate Limits, Throttling, and IP Failures
Problem: Too many requests from the same fingerprint/proxy cause throttles, temporary blocks, or degraded throughput.
Solution: Distribute load across proxies and profiles; implement exponential backoff and failover.
Actionable steps:
- Use a proxy pool and rotate proxies per profile or per N requests.
- Detect HTTP 429/5xx responses and back off with jittered retries.
- Check proxy health before assignment; mark bad proxies and replace.
- Limit concurrent actions per profile to human-realistic levels.
Challenge 5: Captchas and Challenge Pages
Problem: Captchas or additional verification steps halt automated extraction.
Solution: Avoid triggering challenges and prepare fallback flows.
Actionable steps:
- Reduce suspicious behaviors (mass follows, rapid likes) from scraping profiles.
- Route challenge hits to human review or a paid captcha-resolution service only as a last resort.
- Maintain a set of clean, low-risk profiles reserved for sensitive interactions.
Challenge 6: Media Handling and Storage
Problem: Large media (videos, images) increases bandwidth, storage complexity, and can slow pipelines.
Solution: Separate metadata collection from media download; stream or queue media fetches.
Challenge 7: Data Consistency and Duplication
Problem: Re-runs, partial loads, or race conditions produce duplicates or missing fields.
Solution: Use idempotent writes and checkpointing to ensure consistent datasets.
Actionable steps:
- Persist scraped tweet IDs as checkpoints; skip IDs already stored.
- Write in appendable formats (JSONL) with transactional inserts into databases.
- Run periodic dedupe/validation passes and audits (sample counts, missing fields).
Actionable steps:
- First scrape metadata (media URLs), then enqueue downloads to a separate worker using rate limits.
- Store original URLs plus local paths and checksums for integrity.
- Use resumable downloads and retry logic for transient network errors.
FAQ
How to scrape all of a person’s tweets?
To scrape all tweets from a user, you need a systematic approach:
- Use a browser automation or scraping tool (like Selenium, Playwright, or a browser extension) to navigate the profile.
- Handle infinite scroll to load all content dynamically.
- Extract relevant tweet data such as text, timestamps, engagement metrics, and media.
Tools like Multilogin can help maintain separate profiles, manage sessions, and reduce detection risk.
How to download all tweets from a user?
You can download all tweets by combining data extraction and export:
- Use a scraping method to collect tweets into a structured format (CSV, JSON).
- Include metadata like tweet ID, date, retweets, likes, and media URLs.
- Automate the download process with scripts or browser-based tools to capture large volumes efficiently.
How to download all tweets from a user free?
There are free ways to access user tweets, but with limitations:
- Some open-source scripts or browser extensions allow scraping without paid subscriptions.
- Twitter’s official API provides access to recent tweets for free, but it may not cover older posts.
- Free methods often require patience and careful session management to avoid temporary blocks.
How to get all tweets from a user?
To get all tweets from a user reliably:
- Decide whether you’ll use the official API or a browser-based scraping solution.
Set up your environment with proxies or an antidetect browser for safer, long-term extraction. - Implement scrolling logic, data extraction rules, and session persistence to capture every tweet, including replies and media.
- Save the results in a structured format for analysis or archiving.
Conclusion
Scraping tweets from a user is tricky due to Twitter’s anti-bot protections, but with an antidetect browser like Multilogin, it becomes manageable. By mimicking real users, managing sessions, and rotating proxies, you can collect data reliably while reducing the risk of blocks. Always keep legal rules in mind, and focus on efficient, compliant methods to get the insights you need.